
かつて公開していたウェブページでは、より利用しやすい環境を構築するための準備作業として、使用している文字コードをShift JISからUTF-8に変更し、コードが書かれたファイルもANSIからUTF-8エンコードで保存したものに変更中でしすが、デバッグのためにウェブページを表示させると、一部の文字が”?”マークで表示されてしまうことが判明しました。しかも、毎回ではなく時々……。
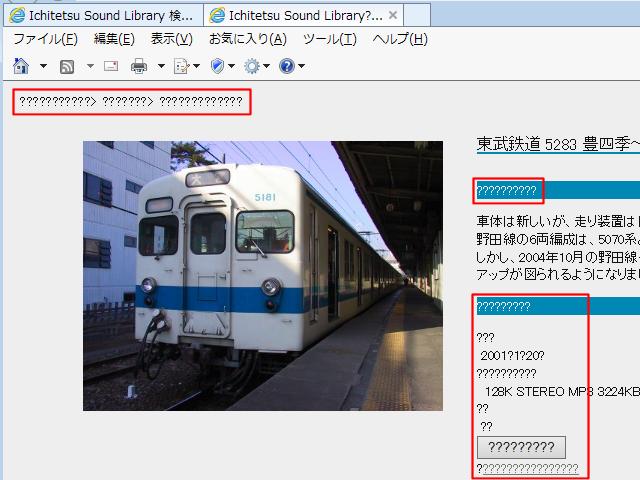
これは、内部でphpを用いて生成したhtmlファイルの例ですが、phpで出力文字列をコーディングしている部分が”?”になってしまい、データ一覧CSV(CSVファイルもUTF-8で保存)から読み込んだ文字列を表示させる部分だけが正しく表示されています。
いろいろとphpのコードを触っても改善しなかったこの現象。調べていくうちに、意外な落とし穴があることがわかりました。
ウェブ検索すると出てくるのは、BOM(Byte Order Mark)というものの存在。ここでは詳細を省略しますが、phpで処理する上で、これがあるかないかが問題の分かれ目となるようです。
たとえば、この詳細を生成するphpコードが書かれたファイルを、バイナリエディタで開いてみます。
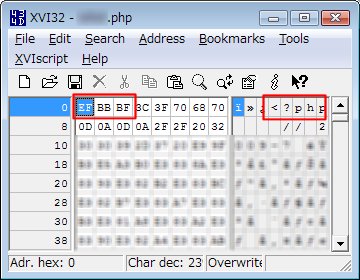
これは、BOMがある状態。”EF BB BF”と、先頭の3バイトで表されているのがBOMで、phpの本体は4バイト目から始まっています。Windows標準の「Notepad」を使用すると、自動的にこの形式で保存されます。
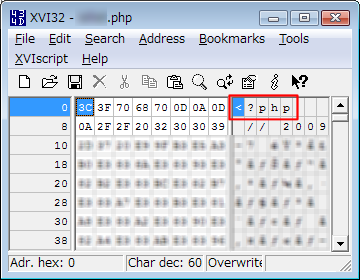
一方、これはBOMがない状態。先ほどのものと比べてBOMがない分、全体が3バイトずつずれていることがわかります。この様式で保存するためには、BOMの有無を選択できるテキストエディタを用いることが必要になります。
調べた結果知ったのですが、UTF-8で保存したphpコードを正しく実行させるためには、BOM「なし」のものを使用する必要があるとのこと。つまり、Windows標準のNotepadを用いてUTF-8で保存すると、問題の発生する可能性のある形式でしか保存できないということです。
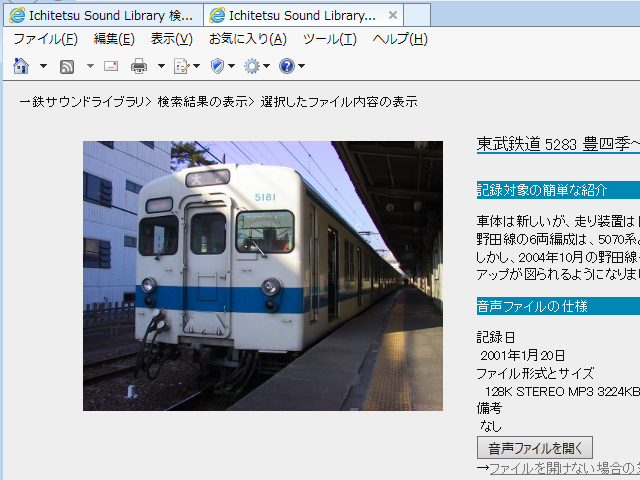
というわけで、BOMのないphpファイルをアップロードして表示させた結果がこれ。念のため様子を見ますが、これで問題は解消するものと考えます。
【2018年12月14日追記】
Windows OSのバージョンによっては、Windows標準のNotepadにおけるBOMなしのUTF-8保存(しかもデフォルト)に対応するものもあります。
【追記ここまで】